클러스터링 결과의 평가는 cluster validation이라고도 한다.
두 클러스터링 간 유사도 측정에 대한 몇가지 제안들이 있다. 이러한 측정법은 한 데이터 셋에서 작동하는 데이터 클러스터링 알고리즘이 얼마나 다른가를 비교하는데 사용될 수 있다.
Internal evaluation
스스로 클러스터링 된 데이터를 기반으로 해, 클러스터링의 결과가 평가된다. 이 방법들은 보통 최고점수를 클러스터간의 낮은 유사성과 클러스터내의 높은 유사성을 가진 클러스터들을 만든 알고리즘에 부여한다. 클러스터 평가에서 internal criteria를 사용할 때 한가지 단점은 높은 평가점수가 반드시 효과적인 정보복원능력(information retrieval application, 대략적으로 말하자면, 본래 데이터내에 가지고 있는 정보를 가능한 많이 손실시키지 않는 범위에서 축약하는것 혹은 그 정도)을 가지진 않는다는 것이다. 덧붙여 이 평가법은 같은 클러스터 모델을 사용하는 알고리즘들에 편향되었다. 예를 들어 k-Means 클러스터링은 본래 object들간 거리를 최적화하는데 , 거리 기반 internal criterion은 이 결과 클러스터링을 과대 평가하기 쉽다. 거리로 객체들간의 거리를 최적화하는데 , 이 클러스터링의 평가를 거리로 한다면, 쉽게 말하면 거리라는 기준 하나로만 인해 클러스터링이 잘된 것일 수록 더 좋은 평가를 얻고 반대로 잘 안된 것일수록 더 안좋은 평가를 얻기 때문에 평가에 편향이 된다는 말이다. 따라서 거리라는 기준 외의 다른 기준평가법을 사용해야 이러한 편향을 줄일 수 있다.
그러므로 내부평가측정은 한 알고리즘이 다른 알고리즘보다 더 나은 성능을 내는 상황들에 대한 약간의 직관을 얻기 위한 상황에서 적합한 방법이다. 그러나 이것은 한 알고리즘이 다른것보다 더 타당한 결과를 제공한다는 것을 의미하진 않는다. 한 지표에 의해 측정된 타당성은 데이터셋 에 존재하는 구조의 종류에 의존한다. 어떤 특정 종류의 모델들에 맞춰진 알고리즘은 그 데이터가 완전히 다른 모델들을 담고 있는지 혹은 평가가 완전이 다른 기준으로 측정되는지를 알수가 없다. 예를들어 k-mean나 많은 다른 평가지표들은 convexity를 가정한다 그러나 non-convex한 cluster를 가진 데이터에서는 k-means나 convexity를 가정한 평가법들 사용하지 않는것이 좋다.
다음은 내부평가지표(interanl crterion)에 기반한 클러스터링 알고리즘들을 평가하는 방법들이다.
1. Davies-Bouldin index

n은 클러스터의 갯수, 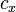 는 x 클러스터의 중앙(centroid),
는 x 클러스터의 중앙(centroid), 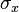 는 x 클러스터내의 모든 요소들의 centroid와 까지의 평균 거리, 그리고
는 x 클러스터내의 모든 요소들의 centroid와 까지의 평균 거리, 그리고 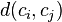 는
는  와
와 간의 거리를 나타낸다. 클러스터간 거리가 가깝고(높은 클러스터간 유사성) 클러스터내의 거리가 멀은(낮은 클러스터내 유사성) 클러스터들을 만든 알고리즘은 높은 Davies-Bouldin 수치를 가질것이기 때문에, 가장 낮은 Davies-Bouldin 수치를 가진 클러스터링 알고리즘이 가장 군집이 잘된 클러스터링으로 평가된다.
간의 거리를 나타낸다. 클러스터간 거리가 가깝고(높은 클러스터간 유사성) 클러스터내의 거리가 멀은(낮은 클러스터내 유사성) 클러스터들을 만든 알고리즘은 높은 Davies-Bouldin 수치를 가질것이기 때문에, 가장 낮은 Davies-Bouldin 수치를 가진 클러스터링 알고리즘이 가장 군집이 잘된 클러스터링으로 평가된다.
2. Dunn index
Dunn index는 (군집 내)밀집되고 (군집 간) 잘 나누어진 클러스터에 초점을 맞춘다. 이것은 최소한의 군집간 거리와 최대의 군집내 거리 사이의 비율로 정의된다, 각 클러스터 분할에 대해, Dunn index는 다음 공식으로 계산된다.

d(i,j)는 i 클러스터와 j 클러스터 간의 거리를 나타내고, d '(k)는 k 클러스터의 클러스터 내 거리를 측정한다. 두 클러스터 사이의 거리인 d(i,j)는 centroid들 사이의 거리 같이 어느 거리측정의 수가 될 수 있다. 유사하게, 클러스터내 거리 d '(k)는 k번째 클러스터에 있는 어느 한짝의 요소들 사이에 최대거리같이 다양한 방식으로 측정된다. 높은 클러스터내 유사성과 낮은 클러스터간 유사성을 가진 클러스터들을 찾기 때문에, 높은 Dunn index를 가진 알고리즘이 더 선호된다.
3. silhouette coeffieint
silhouette coefficient 는 같은 클러스터내의 요소들사이의 평균거리와 다른 클러스터에서의 요소들사이에서의 평균거리와 대조를 이룬다.

각각의 데이터 에 대해서,
에 대해서,  는 같은 클러스터 안에서 와 다른 모든 데이터들간의 평균거리(혹은 비유사성)가 된다. 다시말해 여기서 a(i)는 개체i와 같은 군집내에 있는 다른 개체들간의 평균거리(비유사도)를 나타낸다, b(i)는 개체i와 다른 군집에 있는 개체들사이의 평균거리(비유사도)중 가장 작은 값이다.s(i)가 1에 가깝기 위해서는 a(i)<<b(i)가 되어야 한다. s(i)가 1에 가까워질수록 군집화가 잘된것이고, 반대로 -1에 가까울수록 군집화가 잘 안된것인데, a(i)가 작을수록 군집안의 결집성이 높은것이고 b(i)가 클수록 군집끼리가 멀다는 말이므로 군집끼리의 잘 구분되었다는 의미이다.
는 같은 클러스터 안에서 와 다른 모든 데이터들간의 평균거리(혹은 비유사성)가 된다. 다시말해 여기서 a(i)는 개체i와 같은 군집내에 있는 다른 개체들간의 평균거리(비유사도)를 나타낸다, b(i)는 개체i와 다른 군집에 있는 개체들사이의 평균거리(비유사도)중 가장 작은 값이다.s(i)가 1에 가깝기 위해서는 a(i)<<b(i)가 되어야 한다. s(i)가 1에 가까워질수록 군집화가 잘된것이고, 반대로 -1에 가까울수록 군집화가 잘 안된것인데, a(i)가 작을수록 군집안의 결집성이 높은것이고 b(i)가 클수록 군집끼리가 멀다는 말이므로 군집끼리의 잘 구분되었다는 의미이다.
Exteranl evaluation
외부평가에서, 클러스터링 결과들은 알려진 클래스 라벨과 외부 benchmarks같이 클러스터링을 위해 쓰여진것이 아닌(오히려 분류분석에서 쓰이는) 데이터에 기반해 평가되어 진다. 이러한 benchmark들은 사전분류된 item들의 집합들로 구성되었고 이러한 집합들은 전문가들에 의해 만들어 졌다. 그러므로 benchmark 집합들은 평가에 대한 표준적인 기준으로 생각될 수있다. 이러한 종류의 평가방법들은 미리결정된 benchmark 클래스들과 얼마나 유사하게 클러스터링 되었는 지를 측정한다. 그러나 최근 이것이 실제 데이터에 충분한지 혹은 사실에 기반한 인공적 데이터셋에 의존하는 것이 충분한지, 혹은 클래스들이 내부구조를 담을수 있기 때문에, 특성들에 대한 표현이 클러스터들의 분류를 허용하지 않거나 클래스들이 이상치를 담고 있을수도 있다.
수많은 측정들은 분류작업을 평가하기위해 사용되는 다양한 측정법으로부터 나온다. 한 클래스가 올바르게 한 데이터 포인트에 배치되었는지(True positives)를 세는것을 대신해, pair counting metrics는 실제로 같은 클러스터에 있는 데이터 포인트들의 각 쌍이 같은 클러스터에 있는것으로 예측되는지를 평가한다.
External criterion을 사용하여 클러스터 알고리즘의 질을 측정하는 방법의 일부는 다음을 포함한다.
1. Rand Measure
Rand index는 얼마나 클러스터들(클러스터링 알고리즘에 의해 나온)이 benchmark 분류들과 유사한지를 계산한다. Rand index는 알고리즘에 의해 만들어진 올바르게 분류된 비율의 측정으로 보기도 한다.
TP는 True positive들의 숫자고, TN은 True Negative의 숫자, FP는 false positives의 숫자 그리고 FN은 False Negatives의 숫자를 나타낸다. 한가지 알아야 할점은 false positives와 false negatives가 동등하게 가중치를 가졌다는것이다. 몇몇의 clustering application에 대해서는 이것은 원치않는 특성일 것이다. F측정과 adjusted Rand index가 이러한 단점을 보완했다.
2. F-Measure
F-measure는  파마리터를 통해 재현율에 가중치를 주는것으로 False Negative의 영향도를 균형을 맞추기 위해 사용된다. 다음은 정밀도(P)와 재현(R)의 정의이다.
파마리터를 통해 재현율에 가중치를 주는것으로 False Negative의 영향도를 균형을 맞추기 위해 사용된다. 다음은 정밀도(P)와 재현(R)의 정의이다.

P는 정밀도율 그리고 R은 재현율이다. 우리는 다음 공식을 사용해 F-measure를 계산할 수 있다.

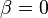 ,
, 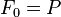 일때를 주의해라, 다시 말해, 재현율은 일때, 재현(율)은 F-measure에 영향을 미치지 못한다., 그리고
일때를 주의해라, 다시 말해, 재현율은 일때, 재현(율)은 F-measure에 영향을 미치지 못한다., 그리고  가 올라갈수록, 마지막 f측정값에서 재현(율)에 더 높은 가중치를 할당한다.
가 올라갈수록, 마지막 f측정값에서 재현(율)에 더 높은 가중치를 할당한다.
3. Jaccard index
Jaccard index는 두 데이터셋사이의 유사성을 수량화한다. Jaccard index는 0에서 1사이의 값을 가지고, 1의 값은 두 데이터가 동일하다는 것이고 0이 의미하는것은 두 데이터셋은 공통점이 하나도 없다는것이다.

이것은 단순히 두 데이터셋에서 공통적인 unique element들의 개수를 전체의 unique elments들의 개수로 나눈것이다.
4. Fowlkes-Mallows index
Fowlkes-Mallows index는 클러스터링 알고리즘과 benchmark classifications에 의해 반환된 클러스터들 사이의 유사성을 계산한다. 높은 값일수록 클러스터들과 benchmark classification이 더 유사하다는 걸 의미한다.

TP는 True Positive의 개수, FP는 False Positives의 갯수 그리고 FN은 False Negative의 갯수 그리고 F-Measrue는 조화평균인 반면, FM은 정밀도와 재현율의 기하평균이다. 덧붙이면 정밀도(precision)과 재현율(recall)은 Wallace's indices, 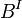 ,
,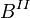 로 알려졌다.
로 알려졌다.
이 외에도 Mutual Information와 Confusion matrix가 있다.
'ML & DM > Clustering' 카테고리의 다른 글
| PAM (Partitioning Around Medroid) (0) | 2016.04.06 |
|---|---|
| DBSCAN(Density-based spatial clustering of applications with noise) Algorithm (0) | 2016.02.04 |
| K-Means Algorithm (0) | 2016.02.03 |
| Clustering (0) | 2016.02.02 |

